
Today, I would like to show you how we can train a data model using the OpenAI API.
Which OpenAI models can be trained?
At the moment, OpenAI allows training models belonging to the GPT3 family:
- Ada
- Babbage
- Curie
- Davinci
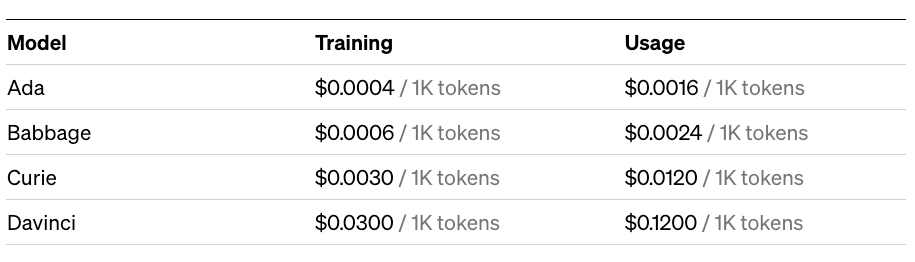
The models have been sorted from the least to the most trained. Naturally, better training of the model comes with a higher price and lower speed of operation.
In practice, Ada is the cheapest, fastest, and least "intelligent" model. On the other end, we have the most expensive model, Davinci, which was sometimes used as a replacement for ChatGPT before OpenAI released the API for GPT-3.5-turbo.
Now we know which model is the least and which is the most powerful, which one should we choose? Unfortunately, there is no definitive answer to this question. It all depends on what we want to achieve, and we need to verify it ourselves.
To choose the right model, we can use the following algorithm:
- Implement a solution to the problem using a small set of data with the default - Curie - model.
- If everything works fine, try switching to the Babbage model. Otherwise, upgrade to Davinci.
- If everything works correctly with the Babbage model, verify the Ada model.
- Once you identify the best model, import the rest of the test data into it.
It is also worth mentioning that besides the GPT3 models, we can also retrain the model that we have created ourselves. Such a model would have data from previous trainings as well as additional data.
Data Preparation
The data for training GPT3 models must have two parts:
prompt = what the user entered
completion = what the model should respond withThe training data needs to be saved as a JSONL document, where each line corresponds to one training example.
{"prompt":"The capital of Polad is", "completion": "Warsaw"},
{"prompt":"The capital of Germany is", "completion": "Berlin"},
{"prompt":"The capital of Czech Republic is", "completion": "Prague"},
{"prompt":"The capital of Egypt is", "completion": "Cairo"},When preparing data for training, it's important to keep a few things in mind:
- The data portion (prompt + completion) must not exceed 2048 tokens.
- A minimum, meaningful amount of data needed for training is 100 samples.
- According to OpenAI guidelines, the
promptshould have a separator at the end (the documentation recommends\n\n###\n\n). - The
completionfield should end with an end-of-completion marker (suggested as\n).
We can prepare the JSONL file manually or use a Python tool provided by OpenAI. To install the tool, we need to execute the following command:
pip install –upgrade openaiIf we want to use this tool, we need to add the API key as an environment variable:
export OPENAI_API_KEY="<OPENAI_API_KEY>"Then, to create the JSONL file, we need to execute:
openai tools fine_tunes.prepare_data -f data_file.csvThe above tool is capable of importing data from CSV, TSV, XLSX, JSON, and JSONL files, verifying and formatting them (e.g., automatically adding separators). If everything goes well, we will obtain a JSONL file that can be used for model training:
data_file.csv (original)
data_file_prepared.jsonl (for training)Creating a New Model
Creating a model boils down to executing a single command:
openai api fine_tunes.create -t data_file_prepared.jsonl -m BASE_MODELBy default, the model will be named starting with the original model name, followed by a colon, then the letters "ft" (for fine-tuning), followed by your organization's name, and the date and time of model creation. For example:
curie:ft-MYCOMPANY-2023-05-23-08-11-48Returning to the fine_tunes.create command, its execution will perform the following actions:
- Sending the training data file to the OpenAI server.
- Creating a job on the OpenAI servers to train the data.
- Sending events to inform us about the progress of the model training.
The training process can take from a few minutes to several hours. It depends on the size of the training data and the backend load (sometimes we may not be the first in the training queue, so we'll have to wait our turn).
It's worth noting that all operations related to model training occur on the OpenAI servers, so pressing CTRL+C in the terminal will not interrupt this process. Calling that shortcut will only disconnect us from the server, but the task will still be executed, and the costs will be charged to our account.
Managing Fine-Tuning
Each fine-tuning request sent to the API receives a unique identifier in the form of ft-XXXXXXXXXXXXXXXXXXXX. By using this identifier, we can manage the entire process.
To cancel a task, you need to execute the command:
openai api fine_tunes.cancel -i IDTo view statistics and information related to a specific task, you can use the command:
openai api fine_tunes.get -i IDIf we have interrupted the process of creating a new model using CTRL+C, we can resume the info streaming using:
openai api fine_tunes.follow -i IDWe can obtain a list of created models by calling:
openai api fine_tunes.listIf we decide that we no longer need a specific model, we can delete it. However, in this case, we should provide the full model name instead of the training task ID:
openai api models.delete -i MODEL_NAMEQuerying Our Model
Querying our model boils down to executing the following request:
curl https://api.openai.com/v1/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{"prompt": PROMPT, "model": MODEL}'
This is it. That was the TL;DR of OpenAI's fine-tuning.
Comments
Anything interesting to share? Write a comment.